概要
本記事では、モデルの学習完了後に表示されるテストパフォーマンスに使われている指標(画像分類モデルのACC含む)とトータルロスについて説明します。
本記事を読むことで、モデルの評価を正しく行い、目的に合った精度の高いAIを作成することができるようになります。

前提
AIの予測結果と実際の結果を用いると以下のように複数パターンの評価を出すことができます。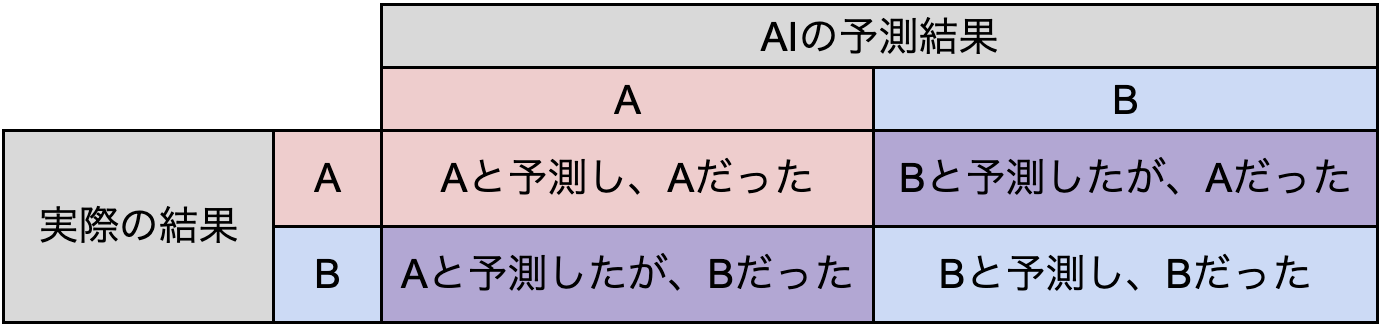
上記複数パターンの評価を使用して、以下で説明する評価指標を算出します。
テストパフォーマンスの指標
以下より、「300枚の画像からセダン、トラック、バスを検出する」という例を使用し、セダンに着目して各指標を説明します。
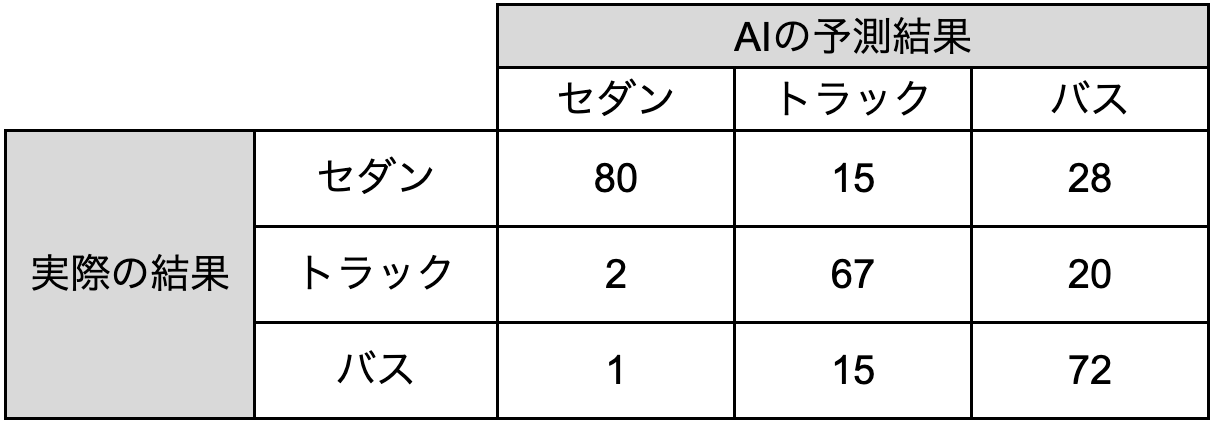
- ACC(Accuracy、正解率)
全体のデータの中で「予測 = 実際の結果」となっているデータの割合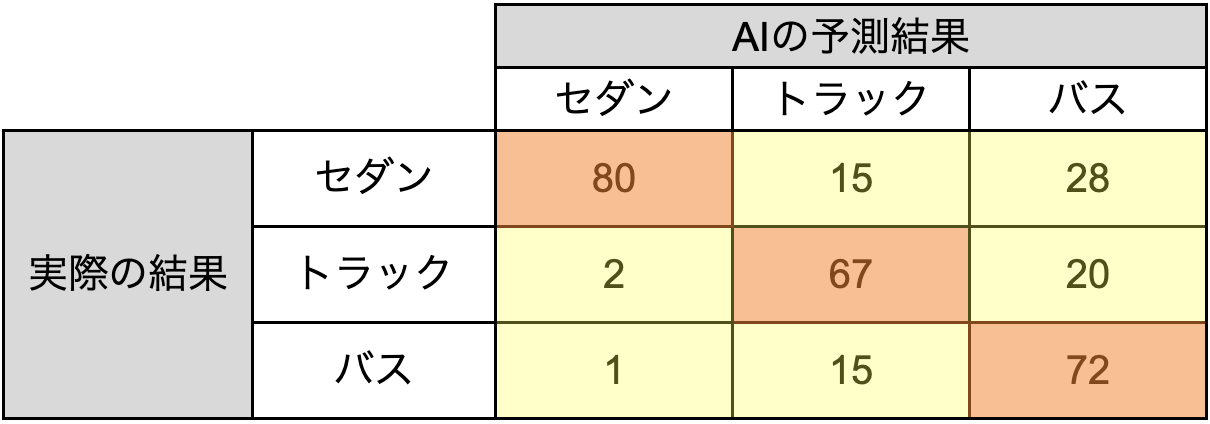
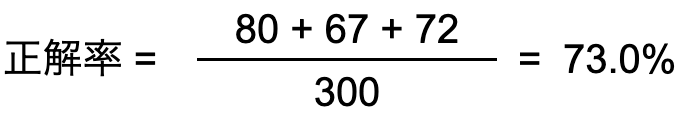
メリット 直感的に分かりやすい
デメリット データに大きな偏りが見られる場合は有効ではない
少し極端な例ですが、以下のようにトラックとバスのデータが少なかったとします。
そうすると、データの多いセダンの検出精度が高い場合、「トラックとバスが全て誤検出しているにも関わらず、正解率は高い」というような事象が発生してしまいます。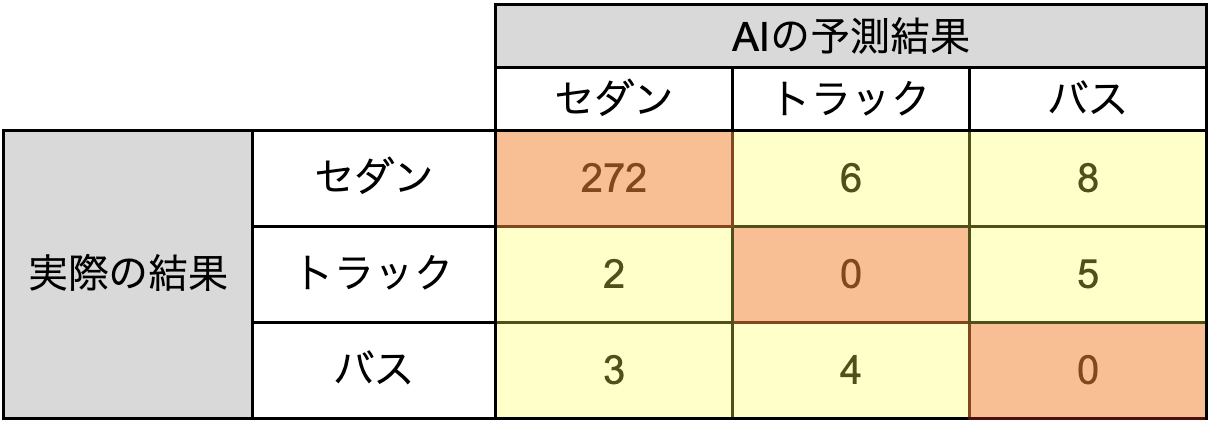
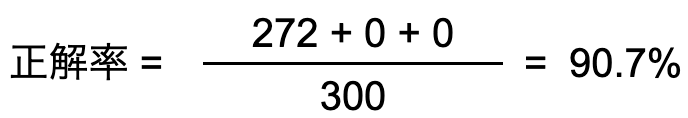
- 平均適合率(物体検知モデルのみ)
平均適合率は適合率と再現率を合わせて評価した値であり、総合的にモデルの精度を評価する際によく使われる指標です。
平均適合率が高ければ高いほど、誤検出も見逃しが少なくなり、物体を正しく検出できるようになってきます。 - 適合率
「セダン」と検出したデータの中で、実際に「セダン」だった割合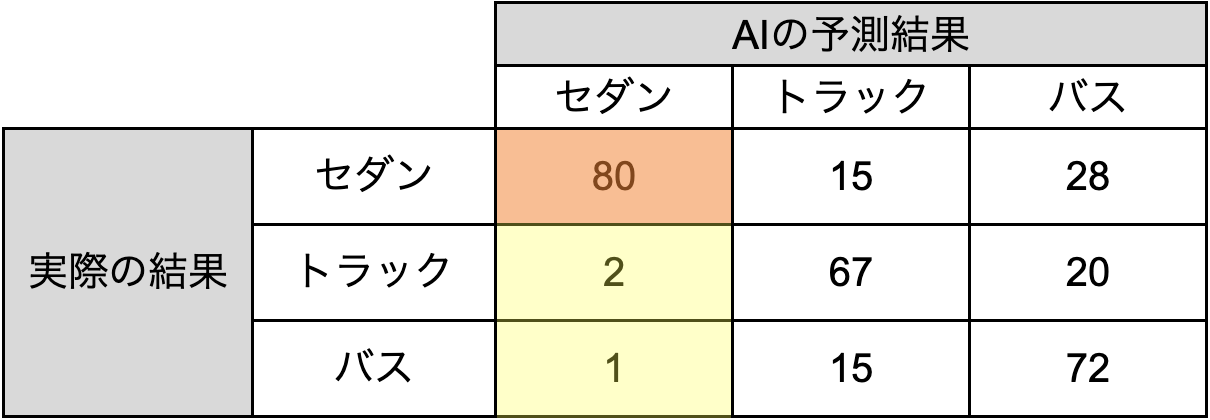

メリット 適合率が高い = 「セダン」と検出した中で「トラック」と「バス」が少ない
ので、誤予測が少ないと言える = 検出した「セダン」の信頼性が高い
デメリット 「トラック」や「バス」と検出したが、「セダン」だったデータを無視しているため、「実はセダンだった...」というデータを見逃している可能性あり
例)工場などで多少の見逃しがあってもいいので、確実に良品だけを検出したい場合(不良品を誤検出したくない) - 再現率
実際に「セダン」だったデータの中で、「セダン」と予測した割合
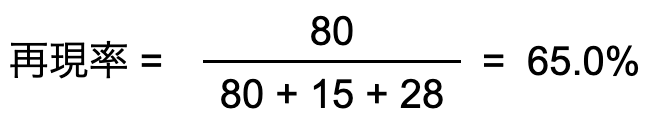
メリット 再現率が高い = 誤って「トラック」や「バス」と検出したデータが少ない
ので、実は「セダン」だった...という見逃しが少ないと言える
デメリット 「セダン」と検出したが、「トラック」や「バス」だったデータを無視しているため、検出した「セダン」の信頼性が低い可能性あり
例)医療現場で病気の兆候を漏れなく検出したい場合(実際病気ではなくても、少しでも疑いがあれば検出したい) - F値
適合率と再現率の調和平均をとった指標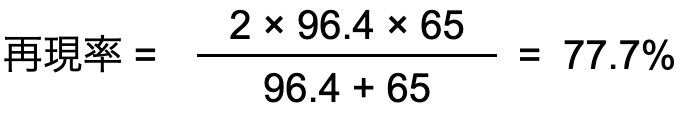
適合率と再現率はどちらか一方が高くなると、もう一方が低くなる性質を持っています。
これまで算出してきた指標を見ると、適合率が96.4%に対して再現率が65%と低くなっています。AIを使用する目的と指標が明確に一致している場合は、適合率と再現率のどちらかを参考しても問題ない場合がありますが、F値が高いと適合率も再現率もどちらも高いと言えるため、どんな目的でもAIとしての精度は高いと言えます。 - しきい値(物体検知モデルのみ)
物体検知モデルには、AIの検出結果に対する自信度が一定の値を超えないと出力しない、という機能があります。その一定の値をしきい値と呼びます。
しきい値のデフォルトは0.5(50%の自信度)となっておりますが、変更することもできます。
値を変えた際に適合率や再現率、F値がどのように変動するかをテストパフォーマンスのグラフで表示しています。
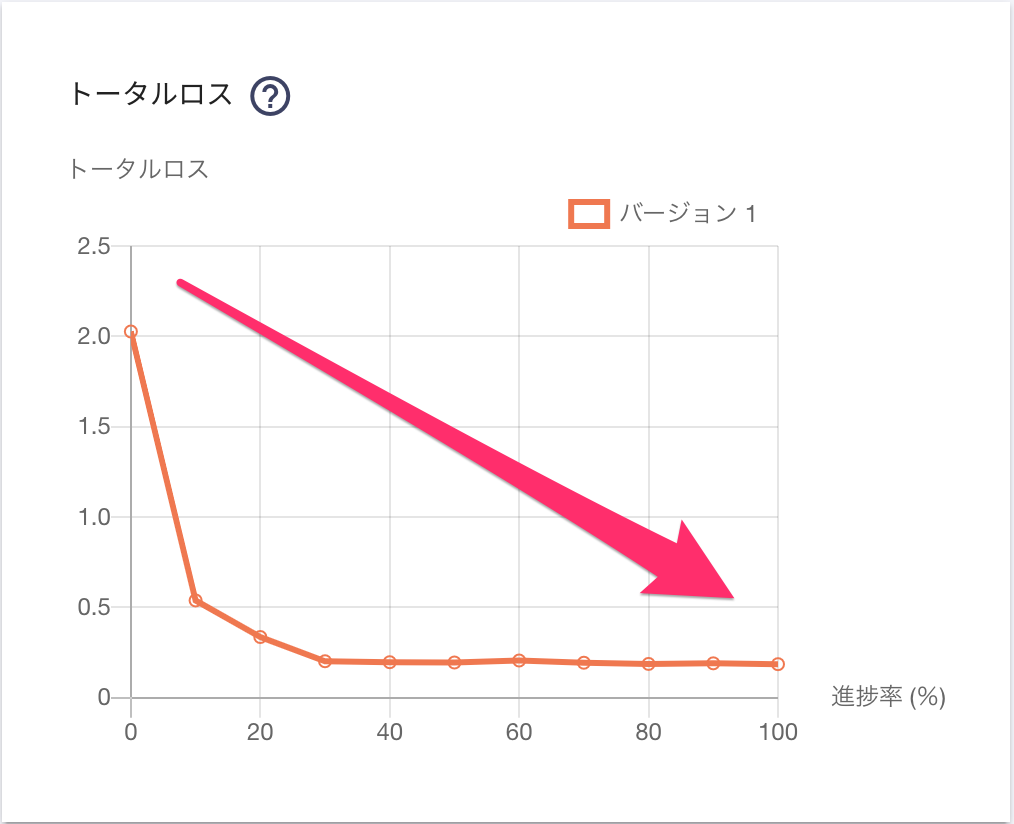
トータルロス
トータルロスとは、モデルによって出力された予測結果と実際の結果のズレを表す値です。
具体的には、ラベルが合致しているかのズレとラベル位置のズレを合計した値になります。
グラフの「進捗率」は学習の進捗率を示しており、基本的には進捗率が増えるほどトータルロスが低くなっていれば「うまく学習できている」と言えます。